You're reading the documentation for a development version. For the latest released version, please have a look at master.
Gray Mod Finder
The Gray Mod Finder pipeline has 3 stages, one is to find the object on gray(RGB) image, then map to 3D space, and finally use alignment to get accurate result.
Pipeline Overview
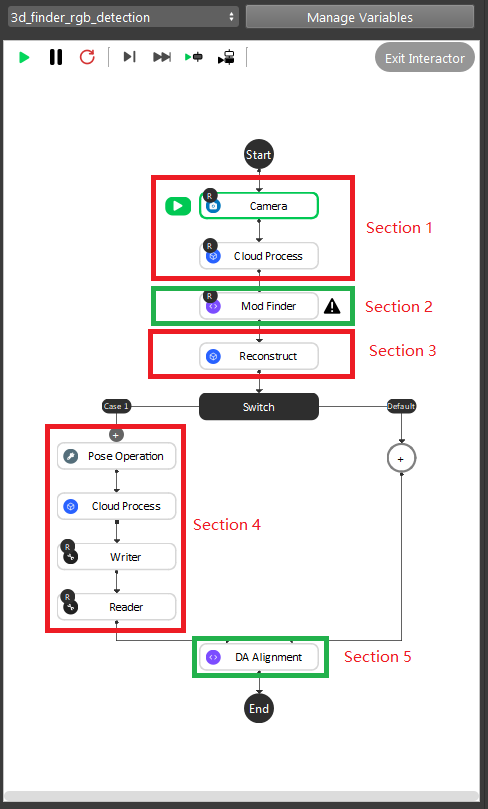
As the image above shows, the Gray Mod Finder contains 5 sections in the whole flow:
Section 1: Used the camera to capture 3D data, then use cloud process (adjust bounding box feature) to set the working cell of the project.
Section 2: Used mod finder 2D mode to find the object in the 2D image.
Section 3: Use the reconstruct node projecting feature to map the 2D result from mod finder node into the 3D space.
Section 4: This section was used to crop the 3D model of the object, and use it for the alignment. And this section will only be executed once during the defining time.
Section 5: The alignment in this section was used to align the 3D model from section 4 into the 3D space. It takes in the output from section 3, where the reconstruct node output the initial pose of the object.
During the runtime, the execution flow is section 1 -> 2 -> 3 -> 5. And during the defining time, the execution flow is section 1 ->2 -> 3 -> 4 -> 5.
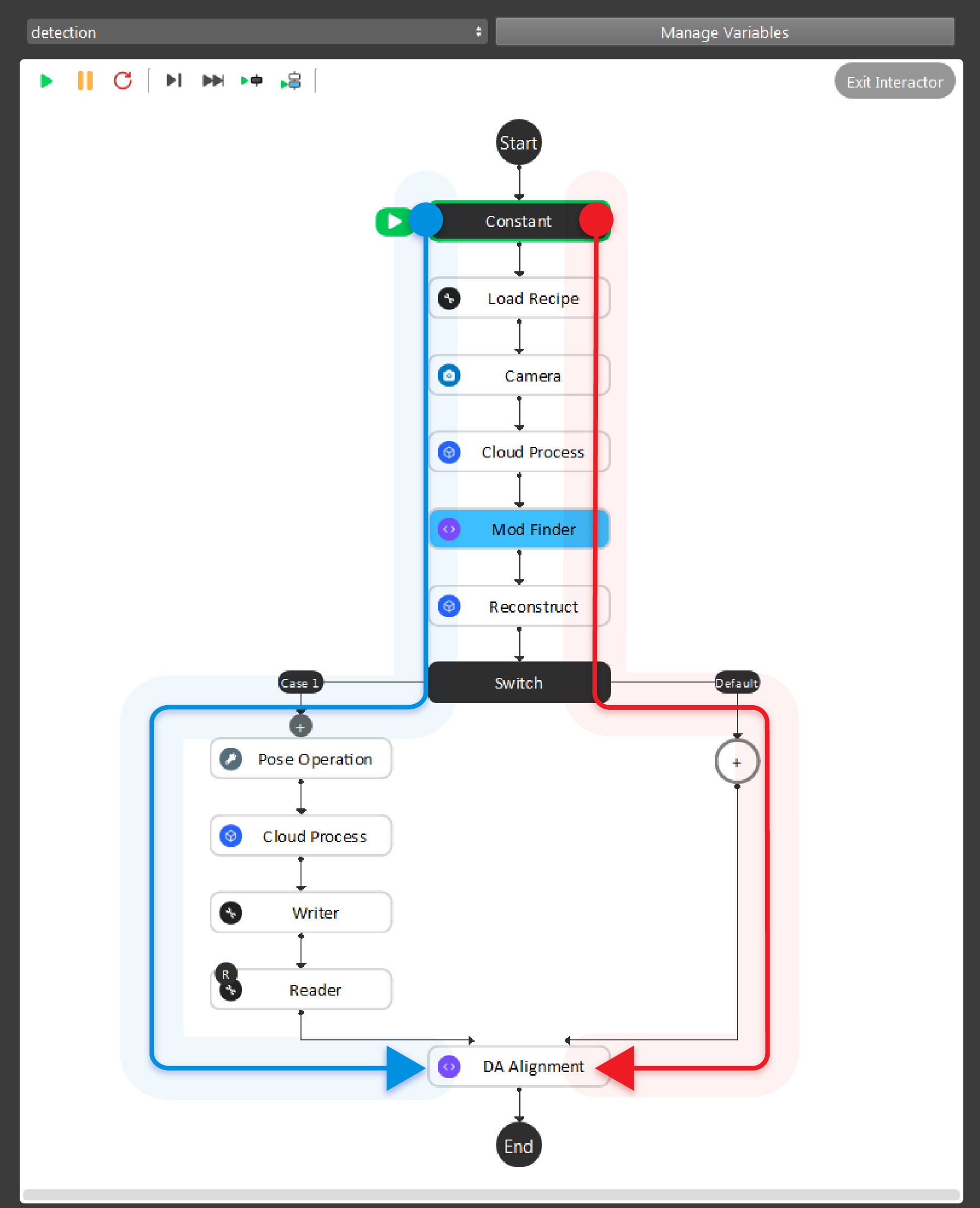
As the above image shows, the red and blue arrow is the data flow for the nodes. Red arrow is the detection flow of the flowchart; blue arrow is the flow for defining model in scene. And more details can be found with this workspace
Tip
You can also learn about the main ideas behind the gray mod finder engine by watching this video tutorial. (TODO, record a video)
Teach model from camera
Teaching an object model is important step when setting up the DaoAI Mod Finder engine to detect objects. Mod Finder needs a good model to identify objects in scene. Mod Finder uses RGB or Depth image to detect objects, therefore anything captured in camera could be possibly the oobject. How can Vision recognizes these objects? By comparing from the model and the image. Hence, good model plays the essential role in this process.
The rest of this article is about how to define model. If you want to know what is good model, please see How to define good models
Placing the object under the camera
Place your object under the camera and try to put it as close as possible to the center of your working environment (center height of the working cell, and at the center of the image) to capture the sample image while making sure that the object is lying fully in the field of view of the camera. It’s useful to run the camera node continously, and turn on the point cloud view to see the image quality of the object.

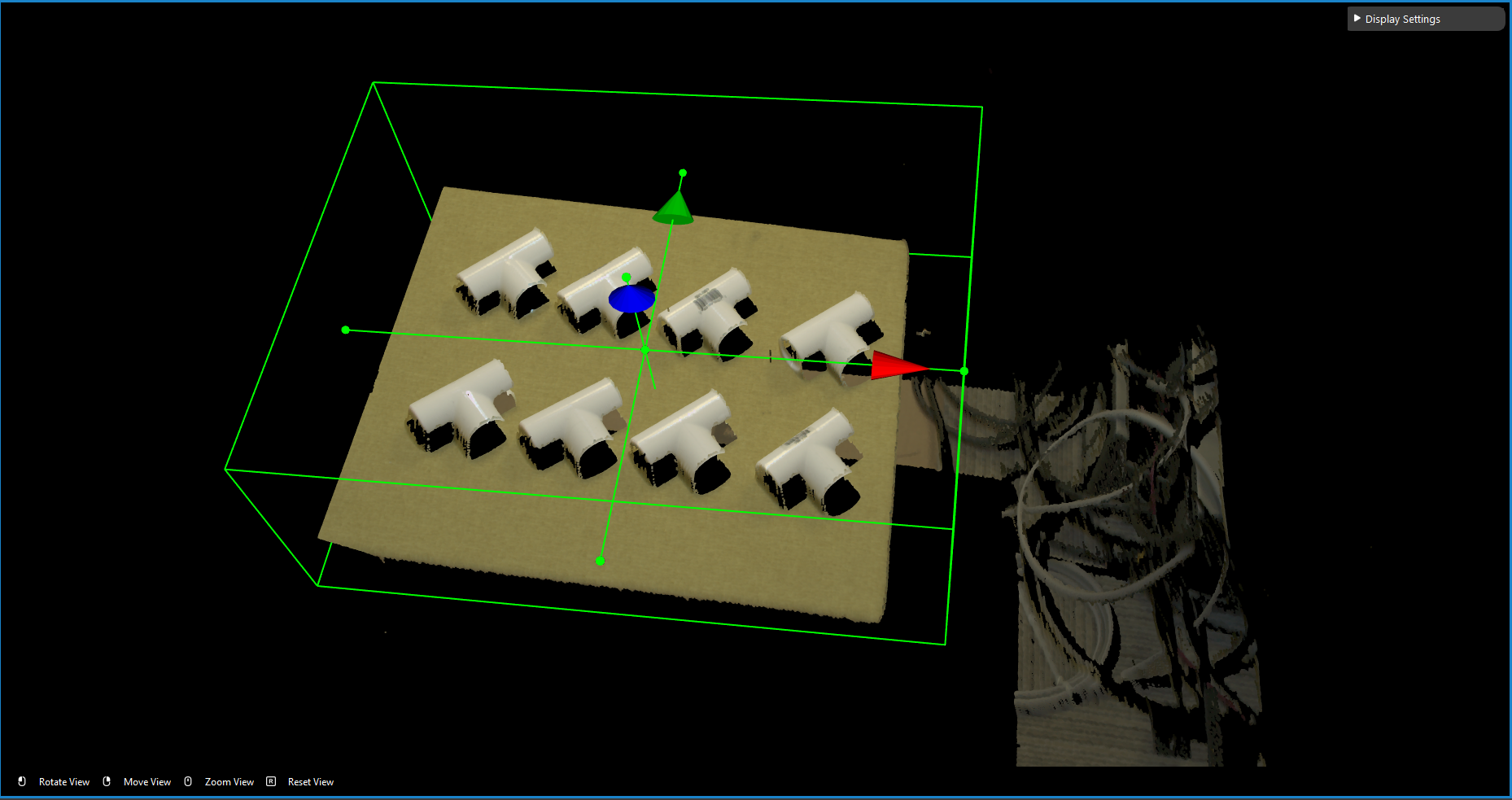
Isolating the object
Usually the camera field of view will be larger than the region of interest, thus the first step usually is to setup the boundary for the useful information. You could run to the first cloud process node, and make sure the Adjust Bounding Box options was on in the cloud process display setting. Then execute the Cloud Process node. Then you could adjust the bounding box.
Tip
When adjust the bounding box, you could press R to reset to the original view, For more information of Adjusting Box. checkout this article.
Define the 2D Model with the Image
Note
Defening a model from scene requires the flowchart in defining mode. Constant node should be set to true in order to switch to defining mode. false represents flowchart is in detection mode.
We use the RGB output from the cloud process node, and now we run the Mod Finder node once to load in the image.
Then click add model, then select a bounding box on the image.
To define a model, click the + sign.
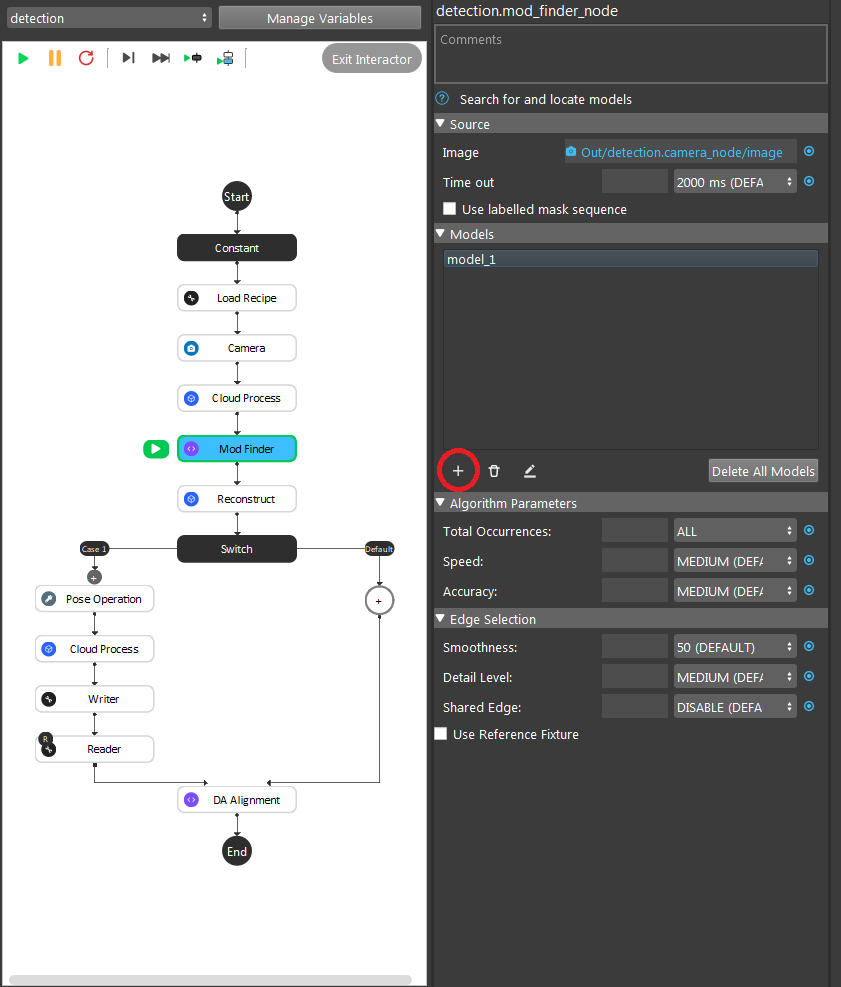
Then defining the model in scene.
