Deep Learning Object Finder 检测流程
本章会详细介绍如何设置 Deep Learning Object Finder 检测流程。

Deep Learning Object Finder 检测流程使用了图形深度学习技术,2D边缘匹配技术和3D点云对准技术,以实现物体的定位和检测。
1. 手眼标定
在创建任务时,需要有已经连接的相机和机器人,然后选择手眼标定文件。如果您还没有完成手眼标定,请参考 机器人手眼标定 来完成手眼标定。
2. 上传深度学习模型
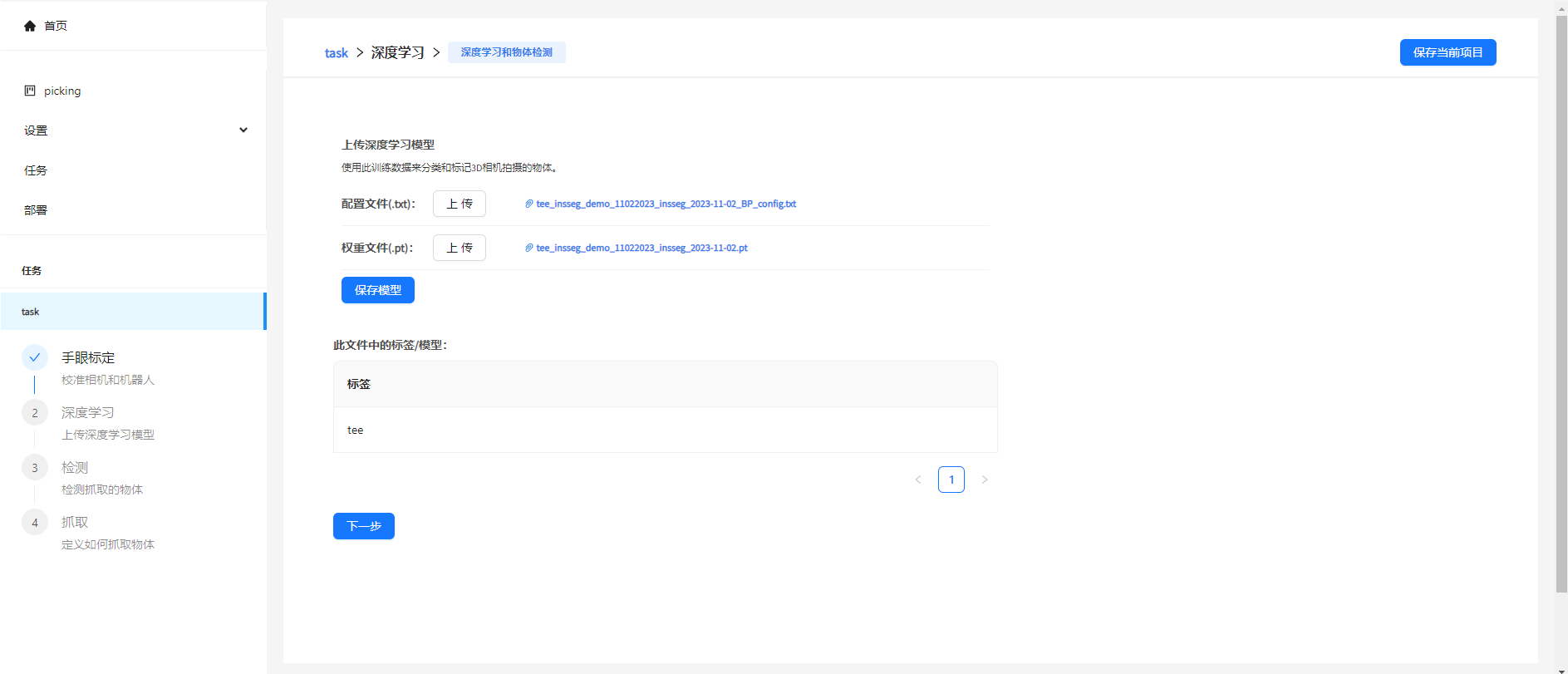
点击上传来浏览深度学习的 配置 和 权重 文件。等上传完成后,点击保存模型。
看到下面的标签栏中出现您的深度学习标签名称,确认正确后,便可点击下一步。
3. 配置检测流程
首先,点击拍照按钮给场景拍照,确认相机正常工作,以及确认物体位置,相机视野是否合适。
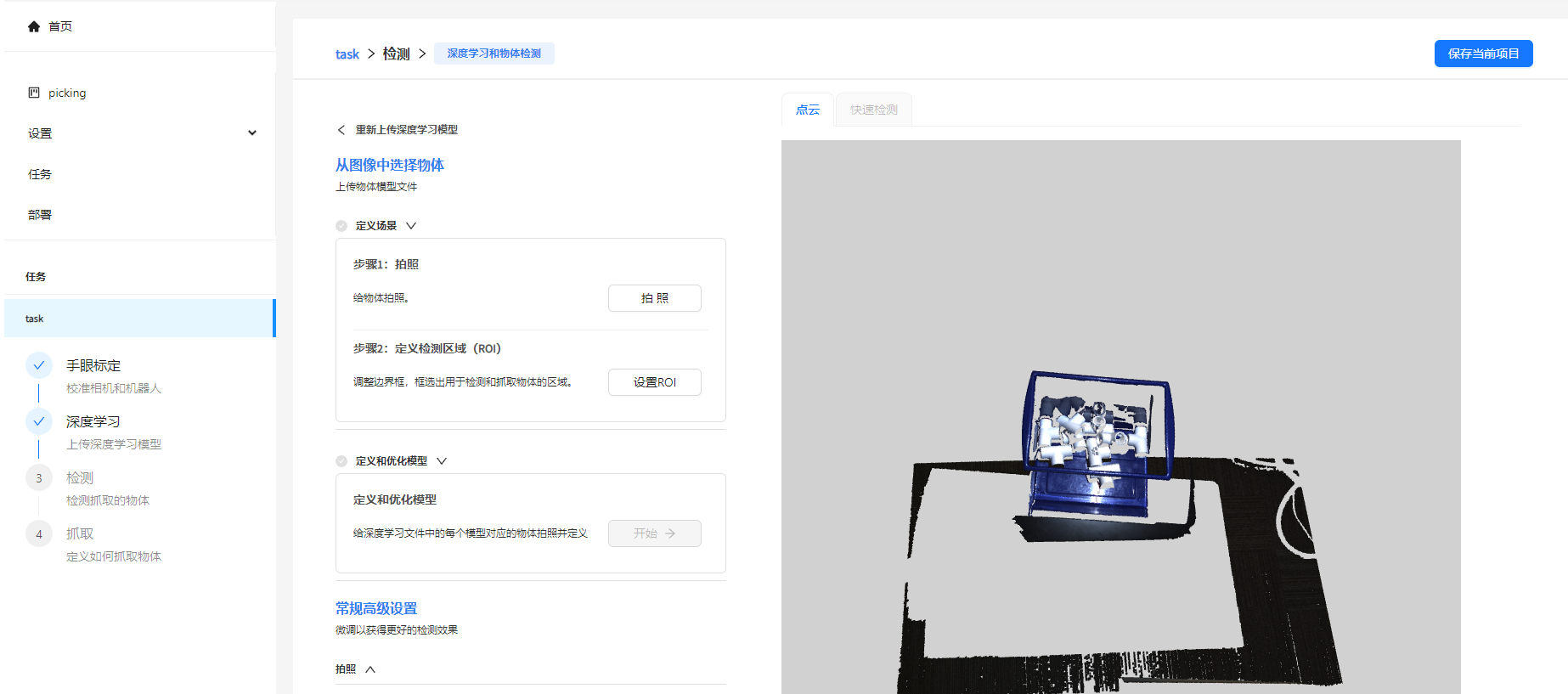
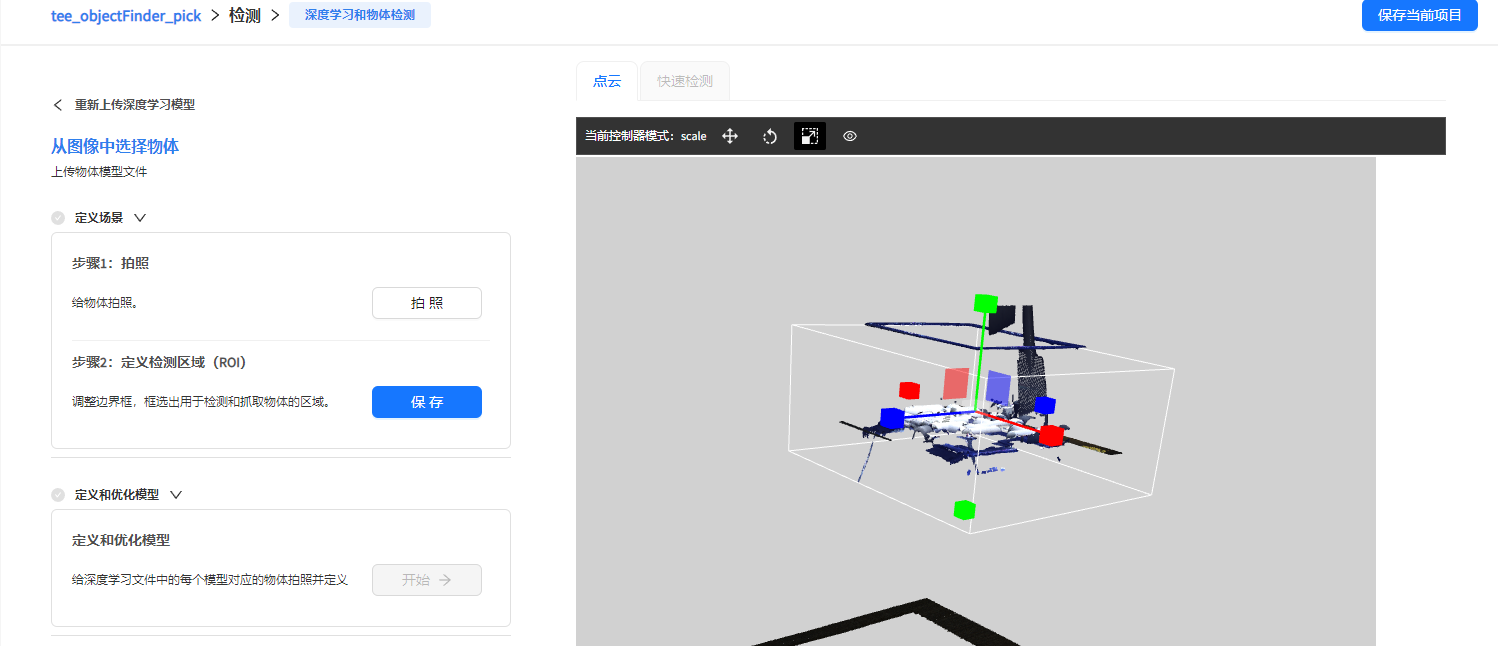
点击设置ROI, 使用窗口中的框截选出检测区域,这一步是为了移除背景,等干扰点云,只保留物体点云会出现的区域,这样可以使检测更快更准。这一步同时设置了参考系,ROI的坐标就是参考系。
小技巧
您也可以框选使得物体所在的平面也被移除,这样只保留物体的点云会最大程度的提高检测速度以及准确度。
备注
ROI的箱体需要和抓取平面保持平行,因为ROI同时设置了参考系,ROI的坐标就是参考系。当之后设置夹爪从上方抓取时,就会以这里定义的参考系的 z 轴为上方。Pick sort的对齐x,y 旋转 也是以参考系为基准。
检查显示窗口的ROI截取的点云是否合适,如果需要修改ROI,请重复1,2,重新设置ROI.
然后就需要定义检测模型,点击开始,然后在右侧物体标签列选中要进行定义的物体标签,在场景中间摆放一个物体,然后点击拍照。
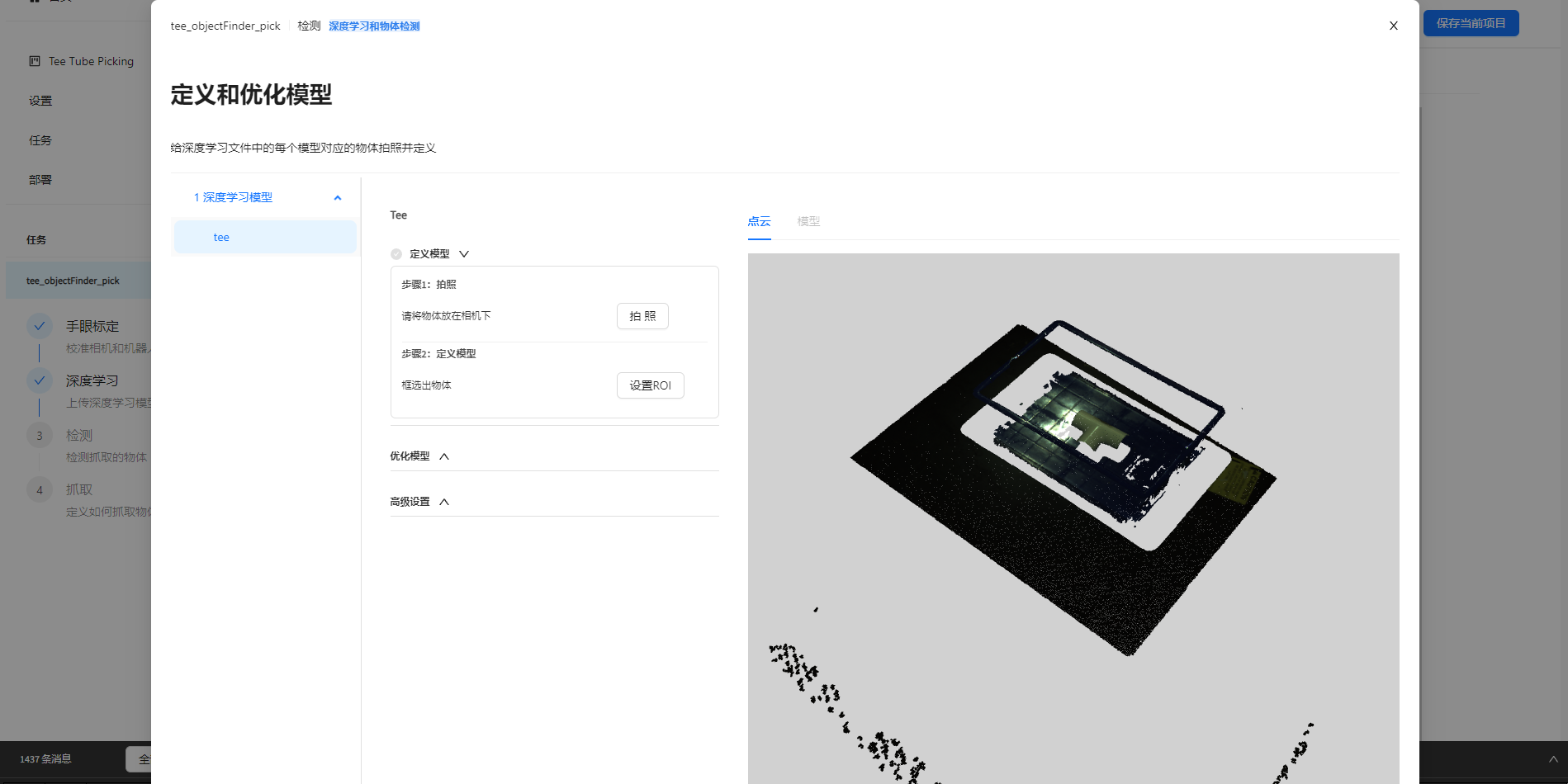
点击设置ROI, 使用显示窗口中的ROI工具,将物体点云框出来,这一步需要只包含物体点云部分,并去除任何不属于物体的部分,然后点击定义模型。
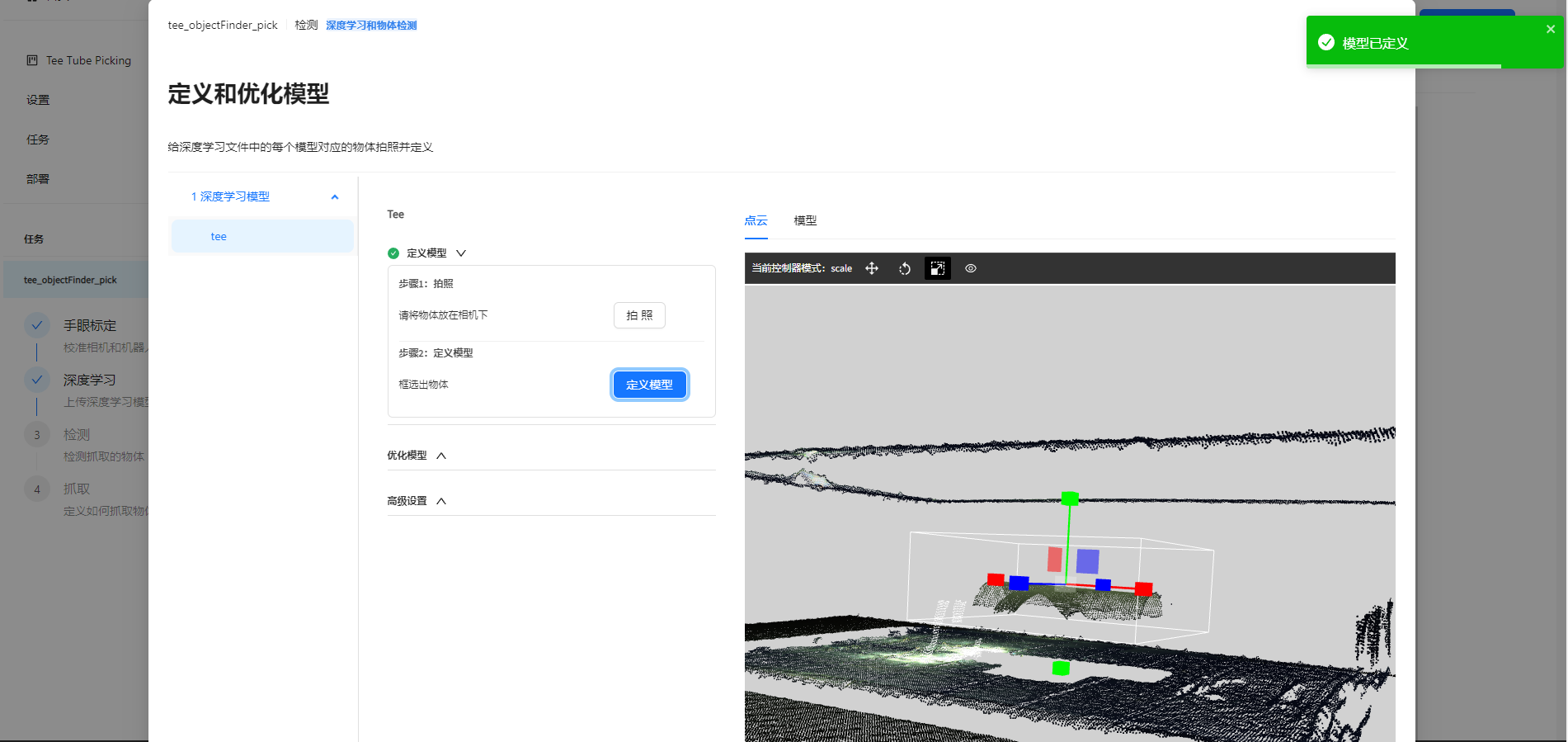
(可选)点击优化模型,然后点击 ‘>’ 箭头开始下一步。 在右边模型图象中点击一个点作为参考点,然后点击保存。
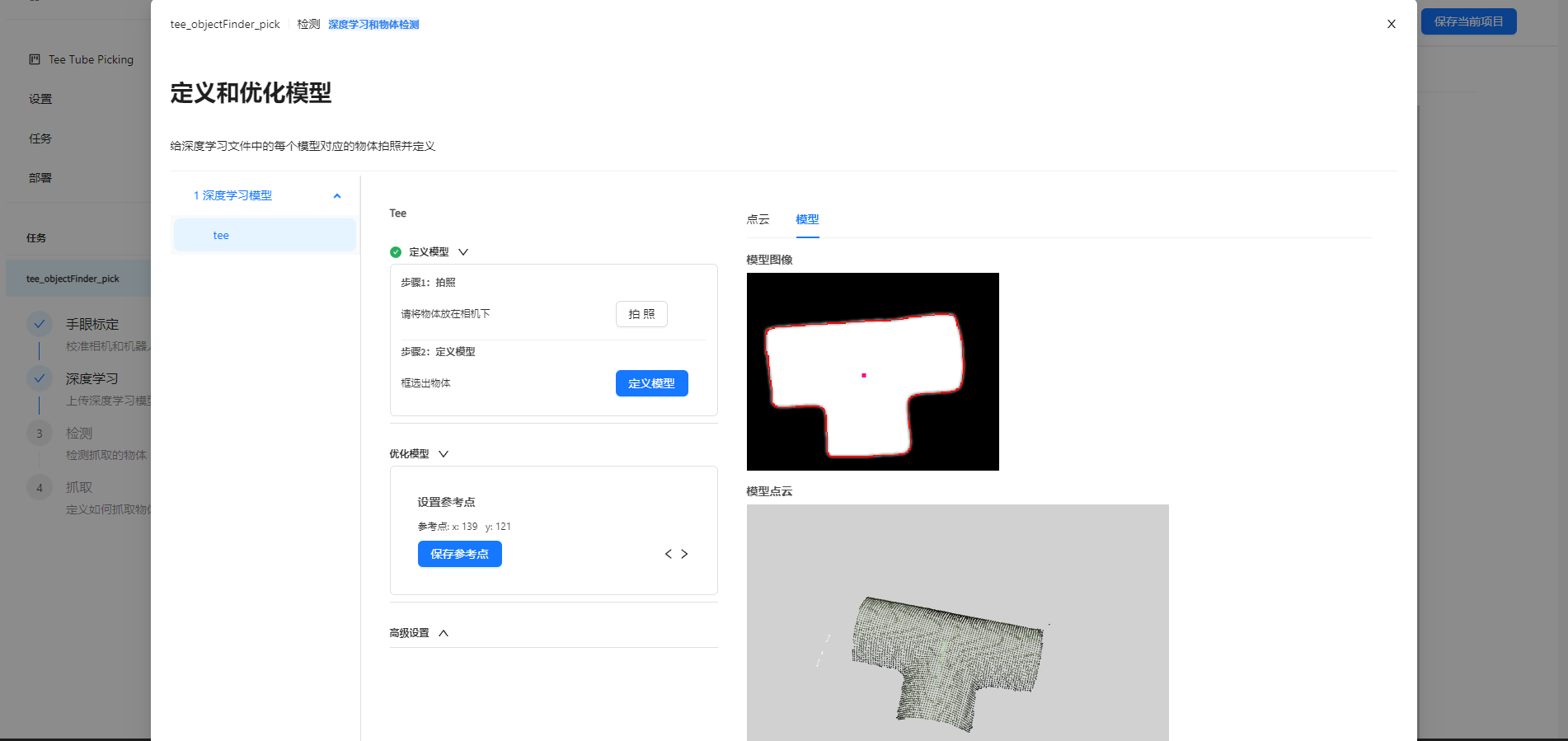
在右边模型图象中,按住鼠标左键进行掩码绘制,这一步需要用掩码遮盖住所有属于噪声的边缘,只保留有效的物体边缘。绘制完成后点击保存。
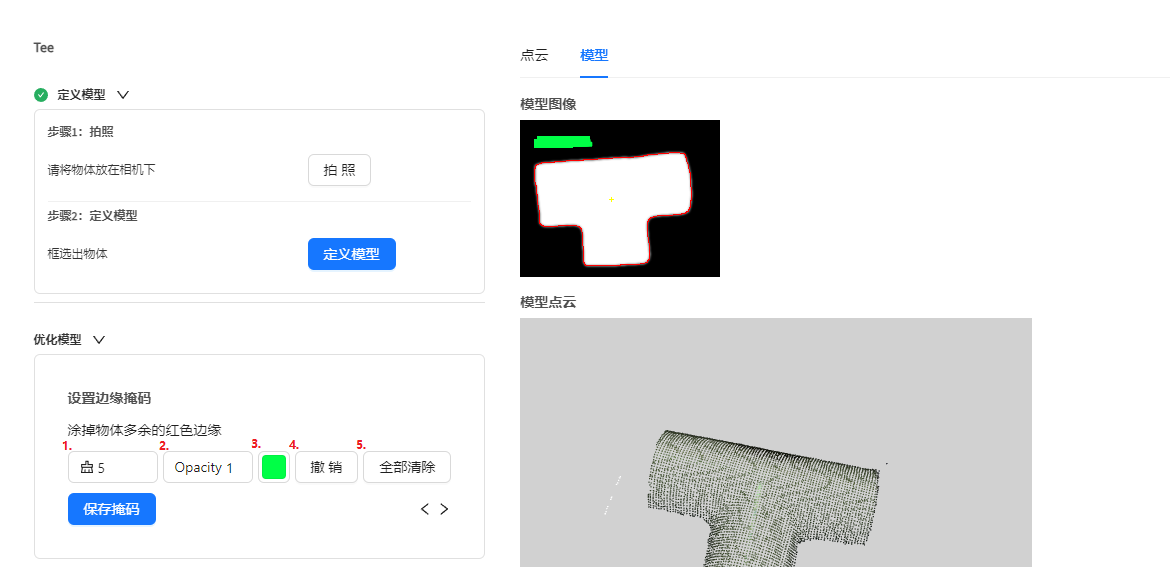
备注
上图中掩码以绿色绘制出来。 掩码绘制的工具: 1. 掩码的笔刷大小 2. 掩码的透明度 3. 掩码的颜色 4. 撤销上一笔的绘制 5. 清除所有掩码
(可选)调试模型的高级设置,更多高级设置详情,请阅读 DL Object Finder 检测流程高级配置

(可选) 调试通用高级设置,更多高级设置详情,请阅读 DL Object Finder 检测流程高级配置
切换到快速检测栏,点击快速检测,下图中绿色部分就是物体模型检测后的结果,请确保物体能够被正确的检测到。如果您的检测效果不佳,请检查1-9的步骤是否正确,更多请阅读 视觉项目优化
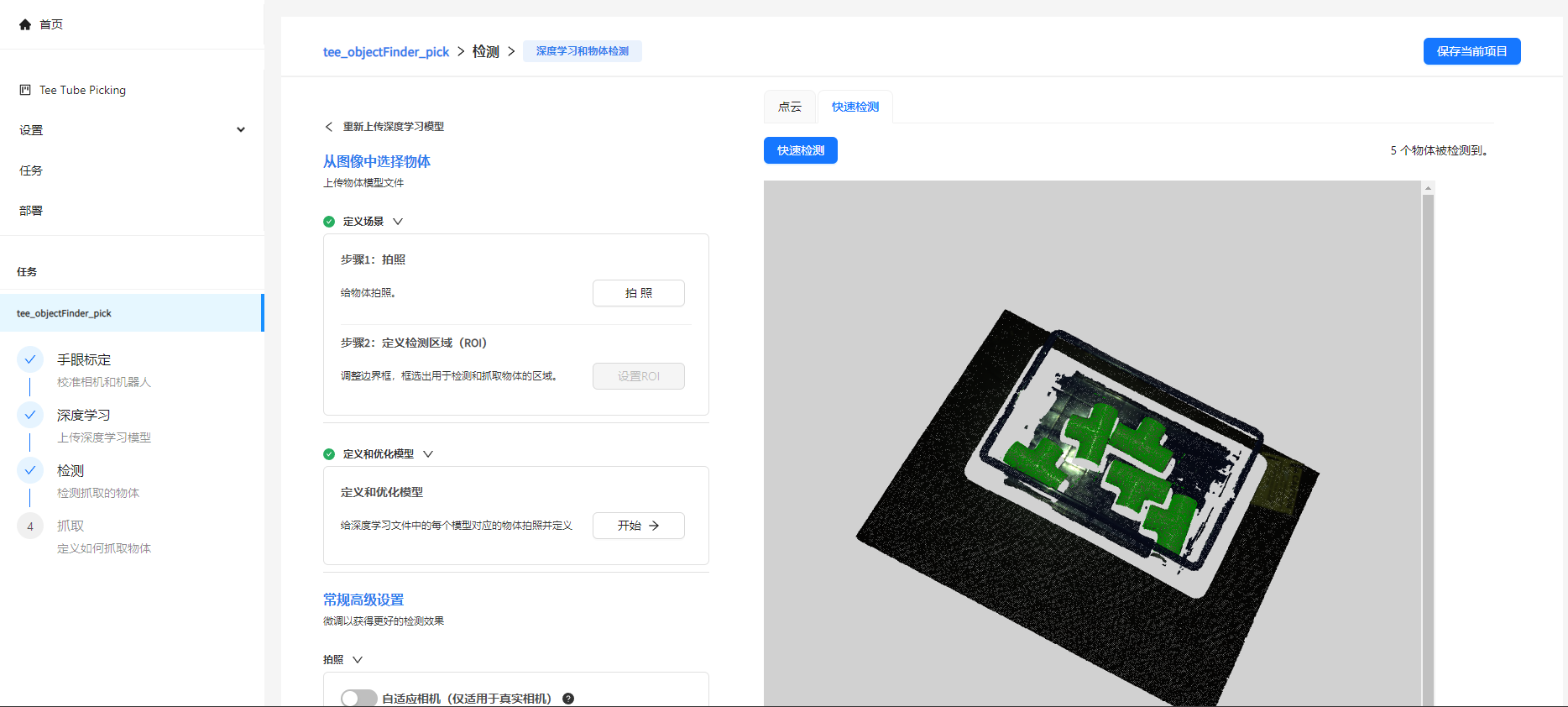
这样检测部分就设置好了,可以进行下一步: 设置抓取策略 。