You're reading the documentation for a development version. For the latest released version, please have a look at master.
Alignment Node
Overview
The Alignment Node uses an iterative algorithm to refine poses for better alignment. Given initial poses, an input model mesh is iteratively aligned toward an input scene cloud by sampling points, matching them between the model and scene, and minimizing the error between matched points.
This node should be used when reasonably accurate poses have already been obtained, such as following after the Reconstruct Node or Mod Finder Node, in which case these poses can be further refined.
Input and Output
Input |
Type |
Description |
|---|---|---|
Hypothesis |
vector<Pose> |
The results of poses. Usually from Mod Finder, Reconstruct etc. |
Scene Cloud |
Point Cloud |
The Point Cloud from scene (Camera, Reader etc.). |
Output |
Type |
Description |
|---|---|---|
poses |
vector<Pose> |
Vector of 3D poses generated from “Hypothesis”. |
size |
int |
Number of aligned poses. |
Node Settings
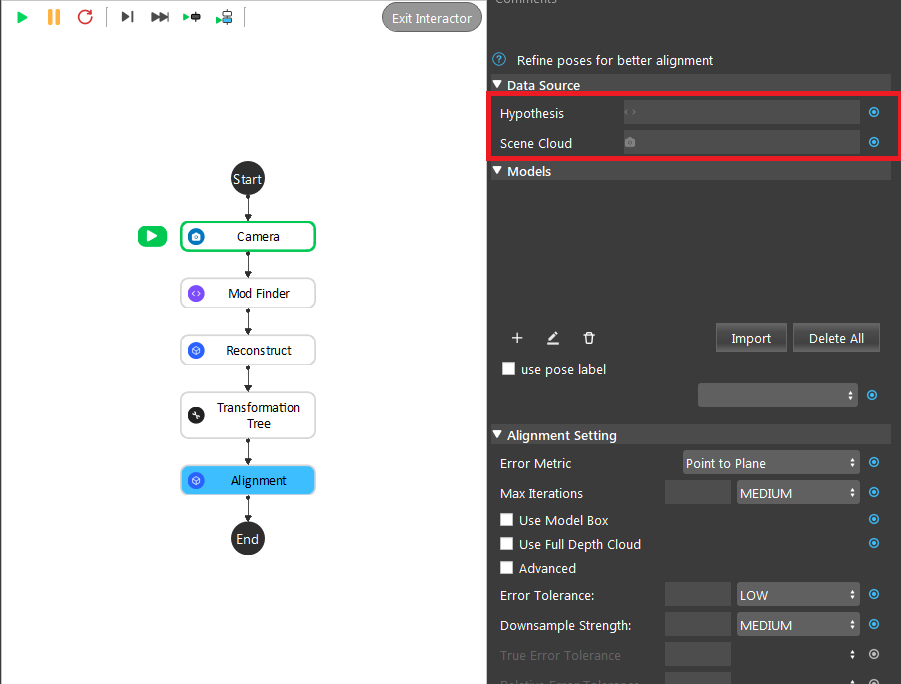
Data Source

Scene Cloud
The Point Cloud from scene (camera, reader etc.).
Hypothesis
The initial guess for the poses, usually obtained from Reconstruct node or 3D Mod Finder node.
Models
Model Type: (Default value: From Scene)
Choose a method to load the model. One of capture from scene, read from file, or link to the output of another node (eg. Cloud Process node).
Model Parameters
Note
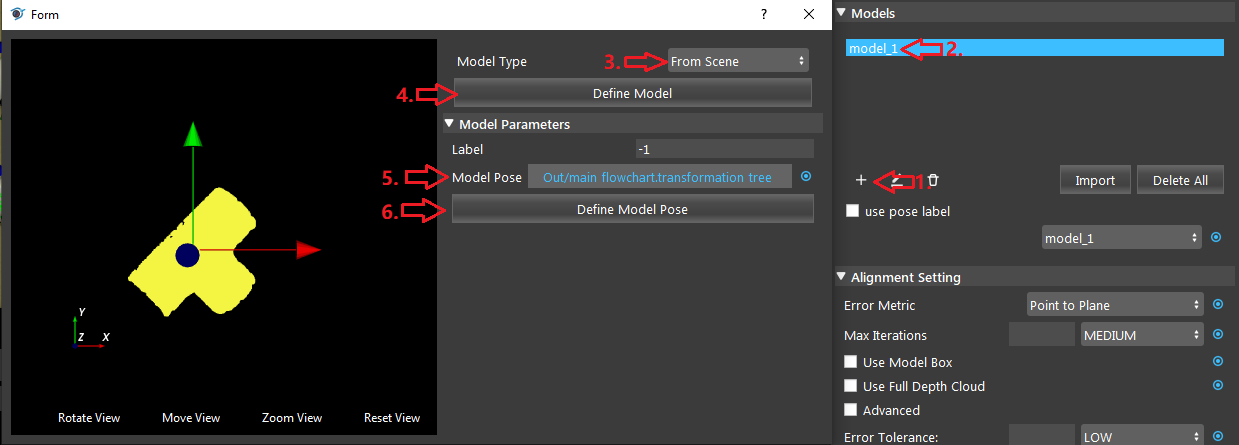
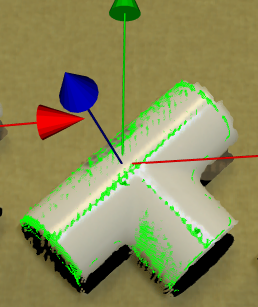
A good model should have the center of axis close to the object as in the image below.
- Model Pose:
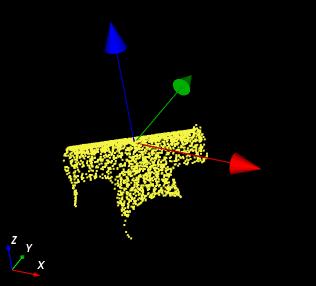
Specifies the object location with respect to the Hypothesis position.
Alignment Setting
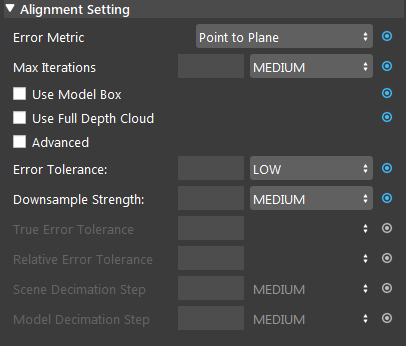
Error Metric: (Default value: Point-to-Plane)
Point-to-Point is representative of the true error, while Point-to-Plane is representative of error relative to orientation. The change of relative pose that gives the minimal Point-to-Plane error is usually solved using standard nonlinear least-squares methods, which are often very slow. Generally, it is recommended using Point-to-Point error metric unless the geometry and amount of overlap between the hypothesis and scene are large to use the Point-to-Plane metric.
Max Iterations: Range [1,∞) (Default value: MEDIUM: 20)
Maximum iteration steps. The higher the number is, the longer it would take for alignment, but the alignment quality will be better with more iteration.
Use Model Box:
If checked, the node will use the model point cloud’s extraction box to limit the points during alignment.
Use Full Depth Cloud:
If checked, the node will use the full depth cloud to compute alignment, this can be helpful when the height difference between objects are large.
Advanced:
If checked, will use advanced error and decimation settings.
Error Tolerance: (Range: [VERY LOW, LOW, MEDIUM, HIGH, VERY HIGH] Default value: LOW)
Available if Advanced is not checked. Controls error tolerance of the alignment. Larger values mean there is more acceptable error.
Down Sample Strength: Range [LOW, MEDIUM, HIGH] (Default value: MEDIUM)
Available if Advanced is not checked. Control overall downsample intensity for the scene and model. Larger vales means stronger downsample.
True Error Tolerance (Advanced): Range [1,∞) (Default value: MEDIUM)
Controls the threshold used to stop iterating when true error is small. Larger values mean more error will be accepted.
Relative Error Tolerance (Advanced): Range [1,∞) (Default value: MEDIUM)
Controls the threshold used to stop iterating when error difference between iteration is small. Larger values mean more error will be accepted.
Model Decimation Step (Advanced): Range [1,∞) (Default value: MEDIUM)
Available if Advanced is not checked. Step size for sampling points in the model. This is similar to Scene Decimation Step.
Scene Decimation Step (Advanced): Range [1,∞) (Default value: MEDIUM)
Available if Advanced is not checked. Step size for sampling points in the scene. The larger the step size means the more points it will skip for the alignment algorithm. Generally, the smaller the step will result in more accuracy.
Procedure to Use
- Link input Hypothesis (from reconstruct, mod finder or 3D object finder node) and Scene Cloud (from Camera or Cloud Process node).
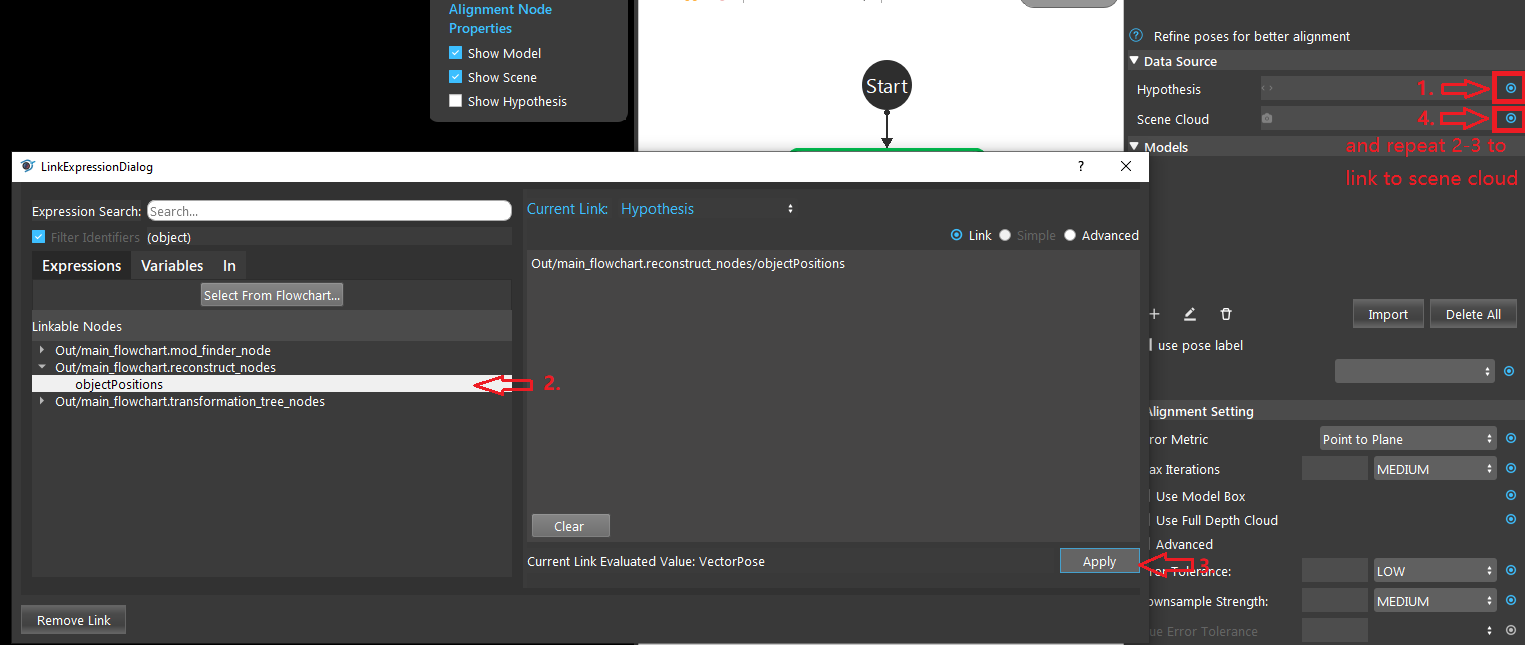
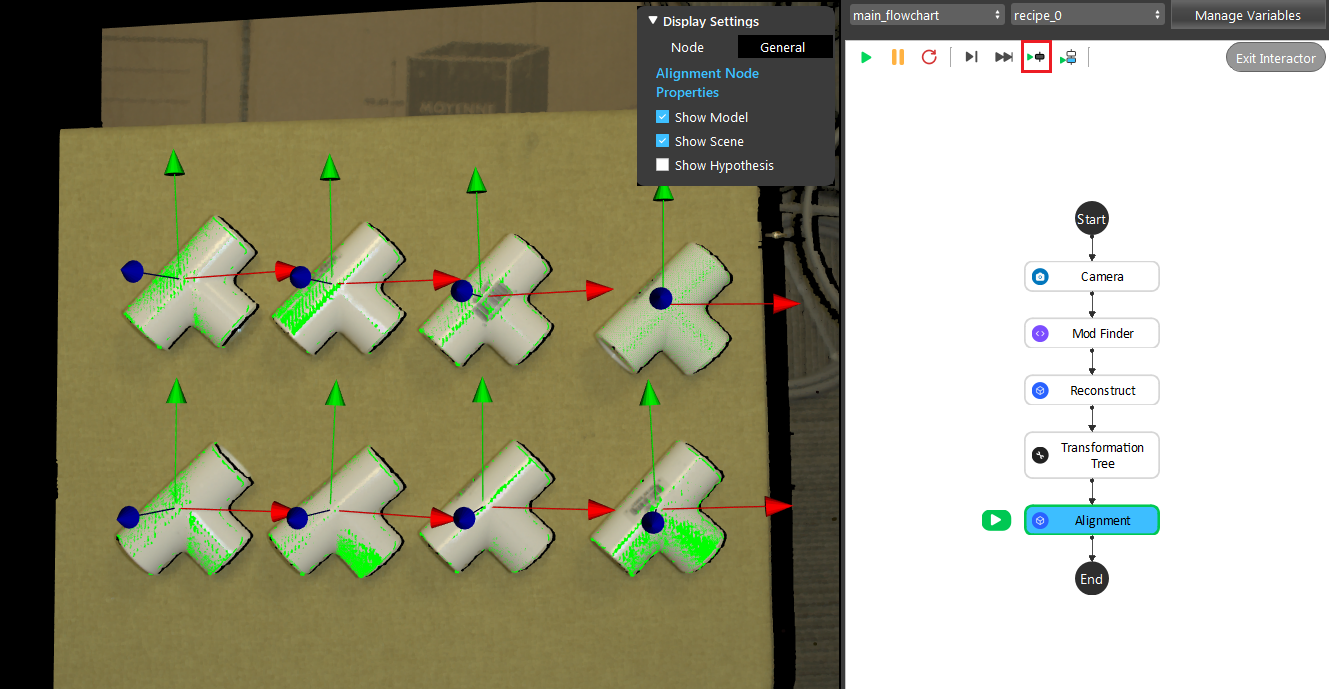
- 1, Click the ‘+’ button to add a model. 2, Double click the creaeted model. 3, You may optionally select how you define your model. 4, Click define model and the model will display on the area to the left. 5, select a pose (link from output of transformation tree) if the axis is far away from the model. 6, Then click Define Model Pose will update the model with the pose given and the axis should be close to the model (like in the image).
You may optionally adjust the node settings
- Error Tolerance: HIGH
- Error Tolerance: VERY LOW
- Run the node, and you should get your alignemnt result on the display window.
Exercise
Try to come up with the setting in Alignment node according to the requirements below. You can work on these exercise with the help of this article. Answers are attached at the end of this exercise.
Scenario 1
There is a project which requires the robot to pick all the occurrences of the T-tube in scene. Your colleague has setup the 3D camera and robot in the lab for experiment. Here’s a link to .dcf file which are used as camera input.
You need to help him setup the Alignment node in main_flowchart. Please choose all correct answers from the options.
- First you will need to link the input, which of the following node should you link to Hypothesis & Scene Cloud?
Mod Finder (2D) & Camera
Camera & Mod Finder (2D)
Reconstruct & Camera
Camera & Reconstruct
- Then you need to define your model from scene, suppose that the mod finder node uses the top-right object as model. Which object should you use as your model for Alignment?

top-right object
top-left object
bottom-right object
bottom-left object
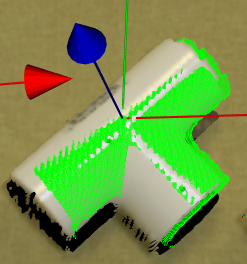
- As the image below, the model defined is off in z-axis (lower than the center of axis). And you find that there is a transformation tree node available. What should you do to bring the object to the center of axis?
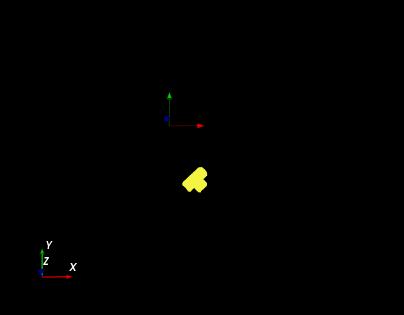
Link the Model Pose to the transformation tree node.
Link the Model Pose to the mod finder(2D) node.
Lower the camera so that it is closer to the object.
Raise the object heigher so that it’s closer to the pysical camera.
Answers for Excercises
Answer: C
Explanation: Hypothesis refers to the less accurate estimate of the objects positions. Mod Finder (2D) will give us only the 2D location, and Reconstruct computes the 3D location from 2D location, hence hypothesis should link to Reconstruct Node. Scene Cloud is captured from Camera and should link to Camera node.
Answer: A

Explanation: Since mod finder node used the top-right object as model, then by default, you should also use the top right object as models. However, you may use other models but it requrie you to do extra settings to the transformation tree node.
Answer: A
Explanation: The transformation tree node is there to help you define your pose transformations, and we should use it.